Week Meal Plan #2 - scraping websites
Continuing the development of Week Meal Plan, we already have a good list of websites that have recipes we can borrow to create our week meal plan suggestion:
- https://marmiton.org (French)
- https://panelinha.com.br (Portuguese)
- https://tudogostoso.com.br (Portuguese)
- https://allrecipes.com (English)
- https://bbcgoodfood.com/recipes (English)
I'll start with Panelinha (Portuguese) because it has super good recipes! First things first: I'll select a single category of recipes and see how it retrieves from server the list of recipes (if it's through an API call or if it's a static rendered page):
I'll start with "Vegetarian" (in Portuguese "Sem carne") recipes category
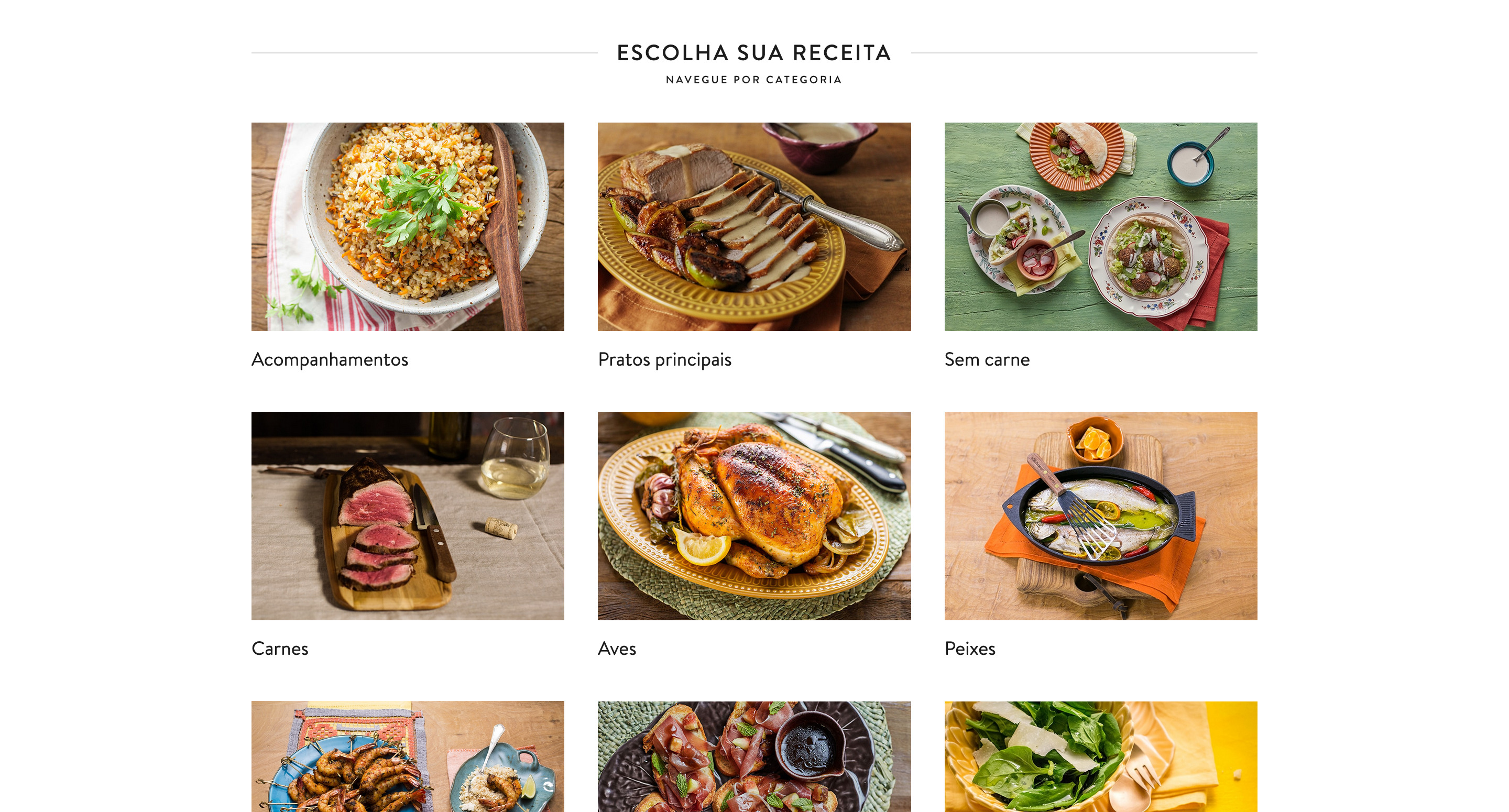
When we click, we're redirect to this url: https://www.panelinha.com.br/busca?pageType=receita&cuisine=vegetariana
Taking a look at network tab on Developer tools, your eyes will shine just as mine when you see this: they do an API call to get the list of recipes!!
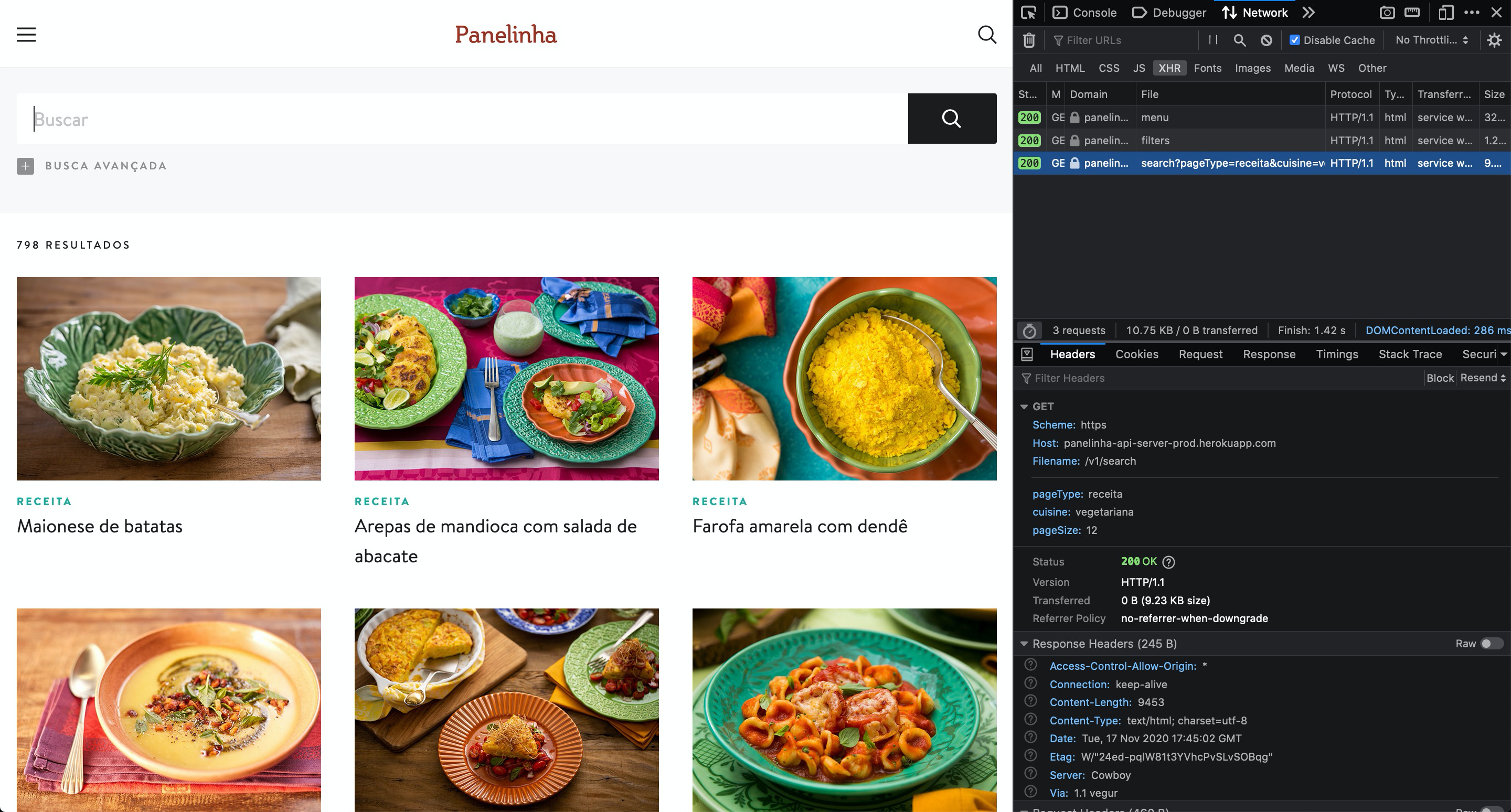
So, let's try on Postman now and change the pageSize parameter and make it 100.
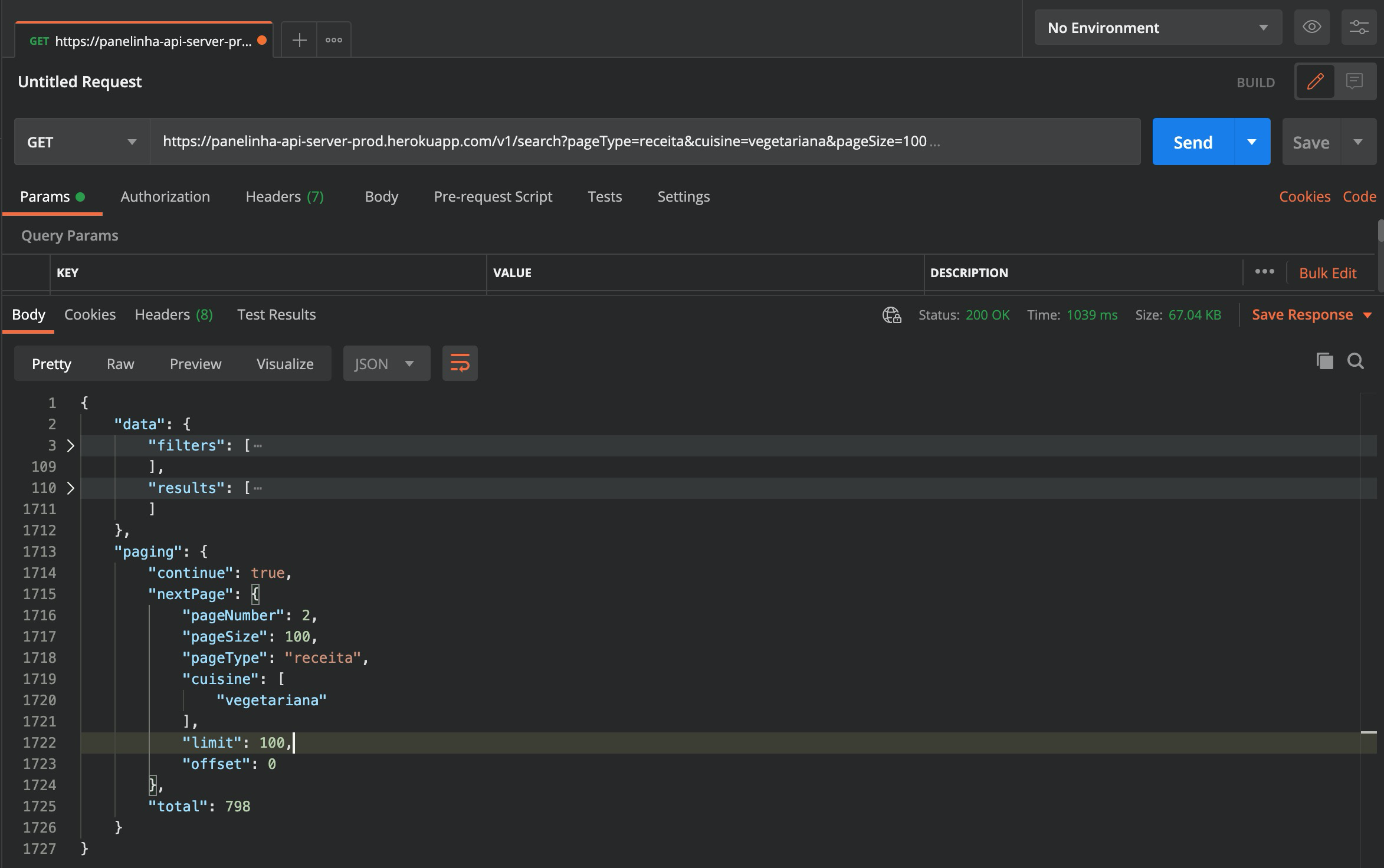
It works beautifully! They have, in total 798 recipes. If we query 100 recipes per call, means with 7 calls we have the list of links to all available vegetarian recipes. Great!
Let's see now how to get a single recipe. When click on a recipe, we're redirect to this url: https://www.panelinha.com.br/receita/maionese-de-batatas
If we compare this URL with the response from the API, we will see that maionese-de-batatas is the slug!
And, checking the network tab, they do an API call to https://panelinha-api-server-prod.herokuapp.com/v1/receita/maionese-de-batatas/null and the response is super-awesome: the entire recipe with all ingredients, step-by-step and images!! Lovely!!
Great! Great! So, what do we have to do now?
- Save all recipes slugs
- Call each slug to get the full recipe and save the JSON response so we analyze it later and think how to store it in a database
I'm super comfortable with JavaScript, so I'll create a simple script that will do this job to me. For the other websites, I might use Python and Beautiful Soup library (because it's easy enough).
Step 1 - Save all recipes slugs
A recursion function will do 90% of our job and another simple function save to a file all slugs
import axios from 'axios';
import fs from 'fs';
const MAIN_URL = 'https://panelinha-api-server-prod.herokuapp.com/v1';
/**
* @param {number} page Page number
* @param {array} slugs Array with slugs from previous request
*/
const getRecipesSlugs = async (page = 1, slugs = []) => {
try {
const resp = await axios.get(`${MAIN_URL}/search`, {
params: {
pageType: 'receita',
cuisine: 'vegetariana',
pageSize: 100,
pageNumber: page
}
});
const recipes = resp.data.data.results;
const paging = resp.data.paging;
const new_slugs = recipes.reduce(
(acc, recipe) => [...acc, recipe.slug],
slugs
);
// paging.continue is provided by the API. Thanks guys =)
if (paging.continue) {
// call the same function passing along the next page and the already retrieved slugs
return getRecipesSlugs(paging.nextPage.pageNumber, new_slugs);
} else {
return new_slugs;
}
} catch (error) {
console.error(
'Failed getting recipes slugs from Panelinha.com.br',
error.message
);
throw error;
}
};
/**
* @param {array} slugs List of all slugs
*/
const writeSlugsToFile = async (slugs) => {
fs.writeFile('slugs.json', JSON.stringify(slugs), (error) => {
if (error) {
console.error('Failed writing slugs to file', error.message);
}
});
};
getRecipesSlugs().then(writeSlugsToFile).catch(console.error);
Step 2 - Call each slug to get the full recipe and save the JSON response so we analyze it later and think how to store it in a database
To do this, we need 2 simple functions: getRecipeBySlug and saveRecipe
/**
* @param {string} slug Recipe slug
*/
const getRecipeBySlug = async (slug) => {
try {
const resp = await axios.get(`${MAIN_URL}/receita/${slug}/null`);
return resp.data.data;
} catch (error) {
console.error(`Failed getting recipe ${slug}`, error.message);
return { error: error.message, slug };
}
};
/**
* @param {object} recipe Recipe in JSON format
*/
const saveRecipe = (recipe) => {
fs.writeFile(`recipes/${recipe.slug}.json`, JSON.stringify(recipe), (err) => {
if (err) {
console.error(`Failed saving recipe ${recipe.slug}`, err);
}
});
};
Then, combining those 2 process, we get our final script
import axios from 'axios';
import fs from 'fs';
const MAIN_URL = 'https://panelinha-api-server-prod.herokuapp.com/v1';
/**
* @param {number} page Page number
* @param {array} slugs Array with slugs from previous request
*/
const getRecipesSlugs = async (page = 1, slugs = []) => {
try {
const resp = await axios.get(`${MAIN_URL}/search`, {
params: {
pageType: 'receita',
cuisine: 'vegetariana',
pageSize: 100,
pageNumber: page
}
});
const recipes = resp.data.data.results;
const paging = resp.data.paging;
const new_slugs = recipes.reduce(
(acc, recipe) => [...acc, recipe.slug],
slugs
);
// paging.continue is provided by the API. Thanks guys =)
if (paging.continue) {
// call the same function passing along the next page and the already retrieved slugs
return getRecipesSlugs(paging.nextPage.pageNumber, new_slugs);
} else {
return new_slugs;
}
} catch (error) {
console.error(
'Failed getting recipes slugs from Panelinha.com.br',
error.message
);
throw error;
}
};
/**
* @param {array} slugs List of all slugs
*/
const writeSlugsToFile = async (slugs) => {
fs.writeFile('slugs.json', JSON.stringify(slugs), (error) => {
if (error) {
console.error('Failed writing slugs to file', error.message);
}
});
};
/**
* @param {string} slug Recipe slug
*/
const getRecipeBySlug = async (slug) => {
try {
const resp = await axios.get(`${MAIN_URL}/receita/${slug}/null`);
return resp.data.data;
} catch (error) {
console.error(`Failed getting recipe ${slug}`, error.message);
return { error: error.message, slug };
}
};
/**
* @param {object} recipe Recipe in JSON format
*/
const saveRecipe = (recipe) => {
fs.writeFile(`recipes/${recipe.slug}.json`, JSON.stringify(recipe), (err) => {
if (err) {
console.error(`Failed saving recipe ${recipe.slug}`, err);
}
});
};
getRecipesSlugs()
.then(writeSlugsToFile)
.then(async (slugs) => {
slugs.forEach(async (slug) => {
if (!fs.existsSync('recipes')) {
fs.mkdirSync('recipes');
}
const recipe = await getRecipeBySlug(slug);
saveRecipe(recipe);
});
})
.catch(console.error);
For the full code and recipes, you can check this on the github repository
Next post we will scrap another website and save its recipes so we can decide on how to store all the recipes in a database.