Week Meal Plan #3 - scraping another website


Hey you! Let's continue scraping websites (well... the first one was only API calls, I know. And I'm not complaining hehehe! Way easier, right?) and this time, let's dive into BBC Good Food Recipes. Again, I'll focus only in one category for the sake of simplicity, and this category will be Quick vegetarian recipes.
Let's repeat the process we did on Panelinha.com.br: we open the website, open developer tools, inspect networks tab and see if they are getting the list of recipes through an API call or if we will have to scrap the webpage.
We have 3 GET requests

And inspecting them, we have:
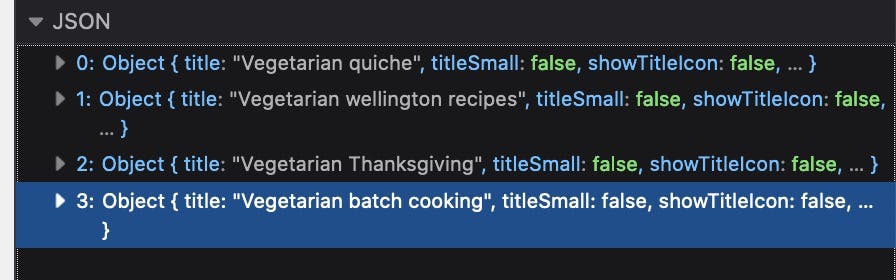
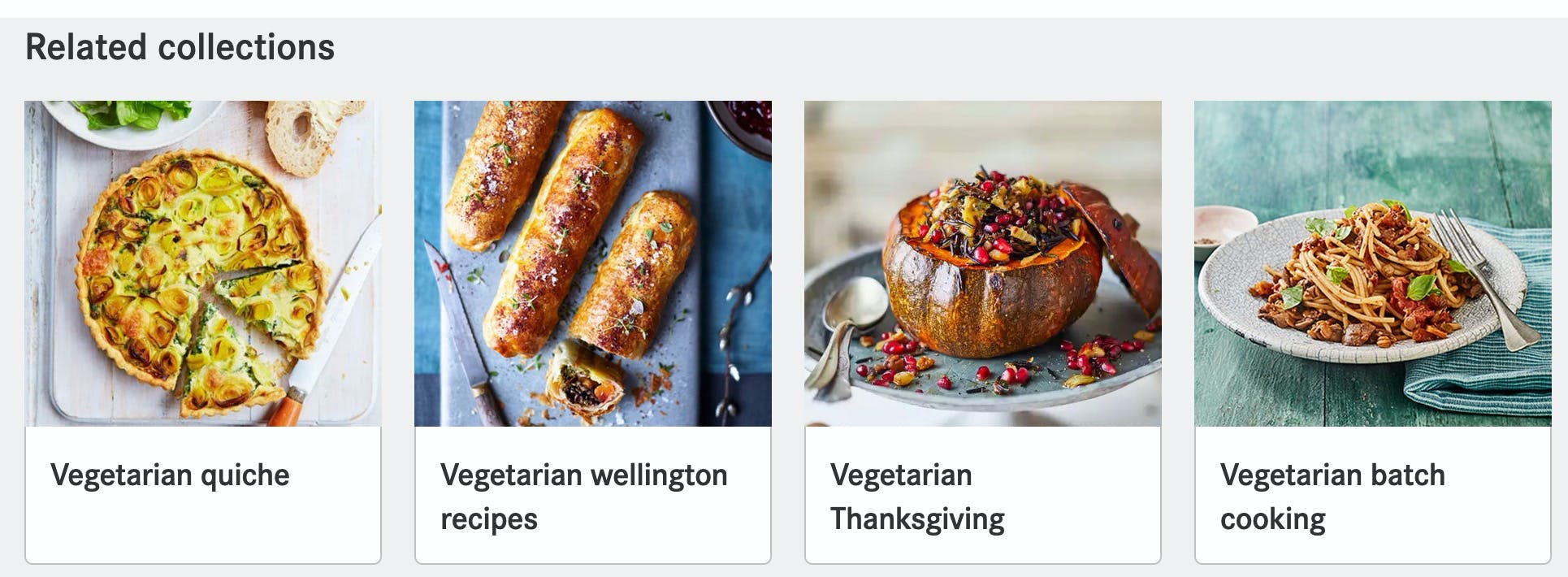
Links for Related collections (look at the title from the response and the title below the food image)
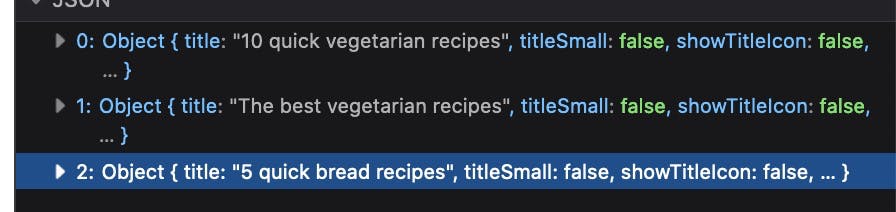
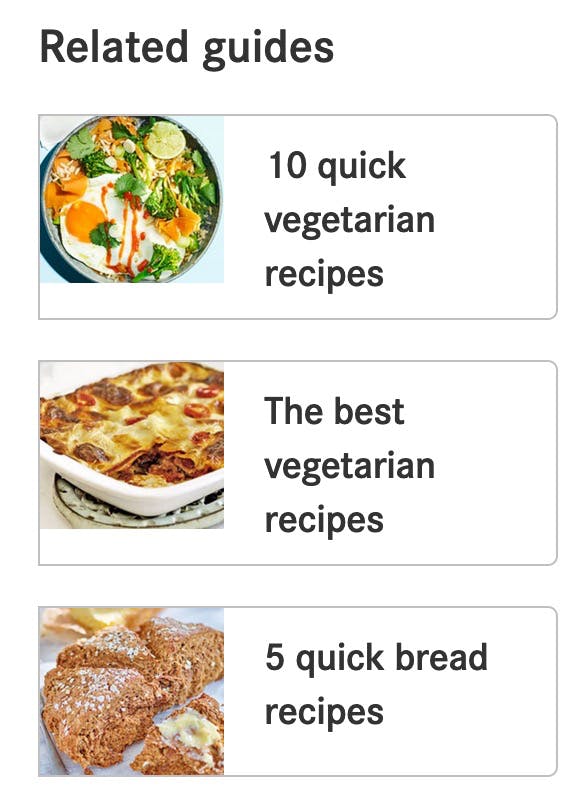
Links for Related guides
Links for Related recipes
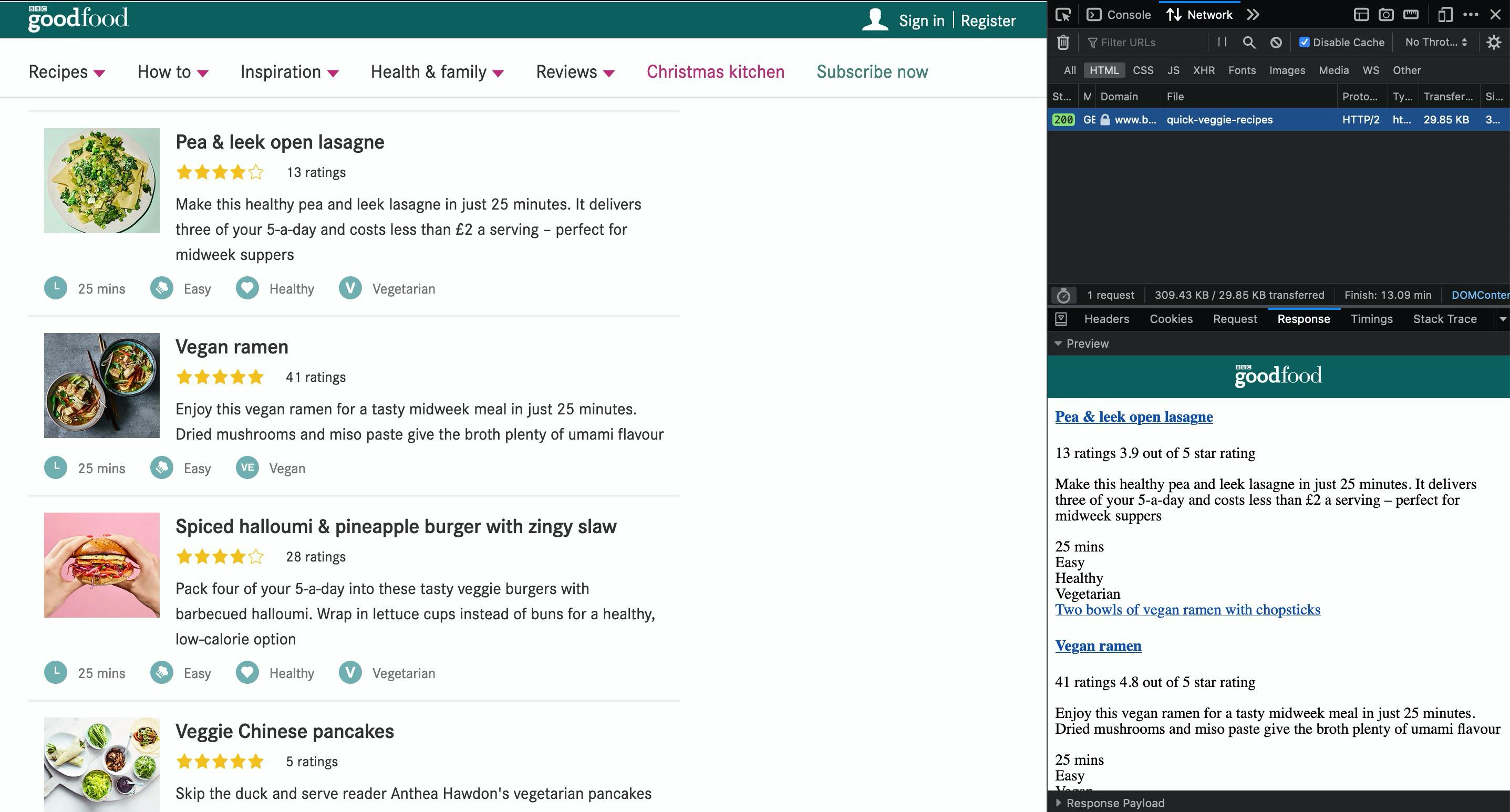
Well... so this website is statically returning with the list of recipes. If we select to display only HTML files in network tab, we see that it's returning only 1 file. And when inspecting it, we can see that our list of recipes is there
No problem... let's scrap this using Node.js. Instead of using Puppeteer - common and powerful choice, I'll be using something lighter and simpler: jsdom. I use this to write tests, but it's a great tool for webscrapping static html pages too.
When scraping a website we can enter in an infinite loop trying to get everything from everywhere. Let's focus here on 1 simple task: the URL for the recipe. With the inspector tool opened, we can see what are the CSS classes for the
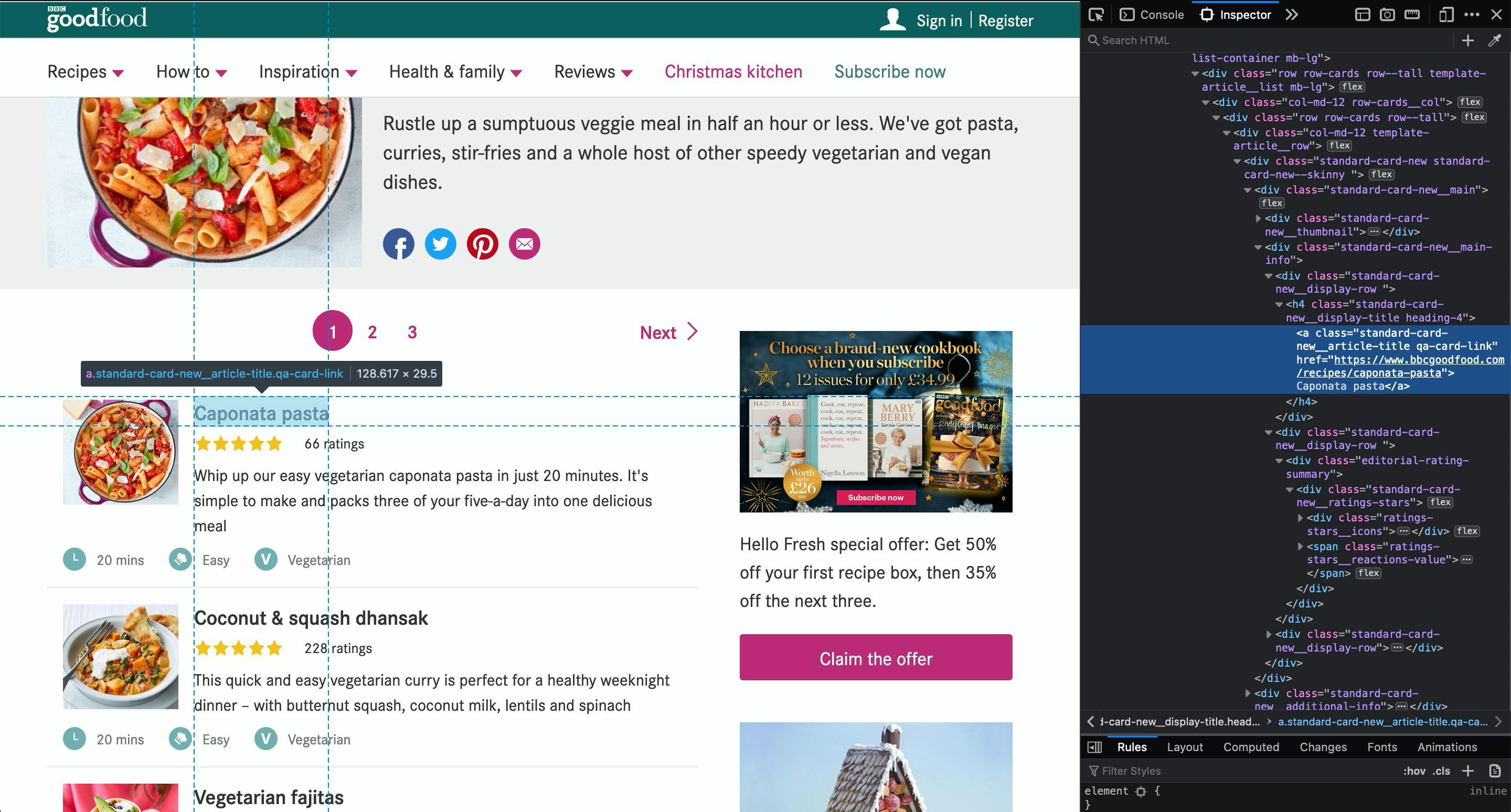
Let's do a simple test on the browser and see the result. Let's get all elements that have those 2 class combined: standard-card-new__article-title qa-card-link:
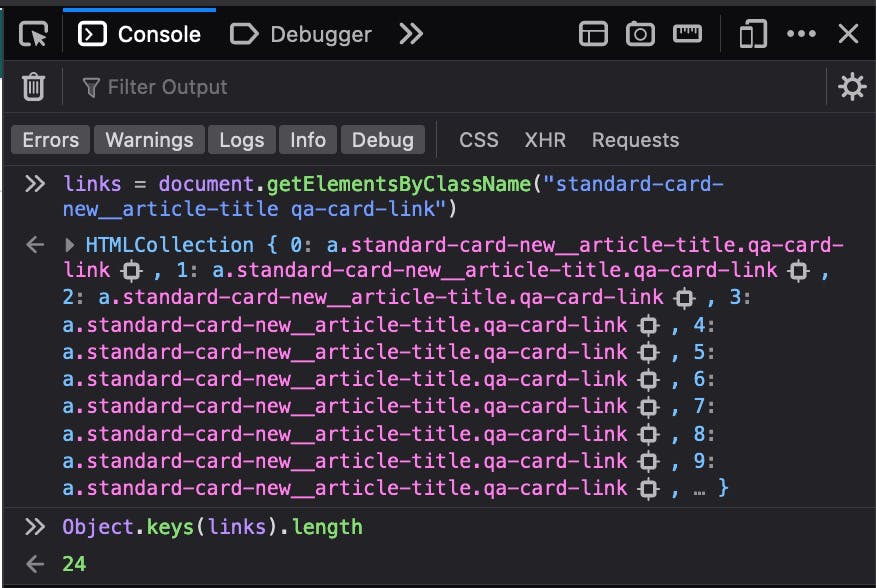
It found 24 items. And, how many recipes are being displayed? 24!! Bingo!!! Yey!! Cool! So, we already know how to get the URL for each recipe. Great! Now, let's focus on the the 2nd task: discover how many pages we will have to load and scrap.
Using our inspector tool again, let's inspect the pagination links
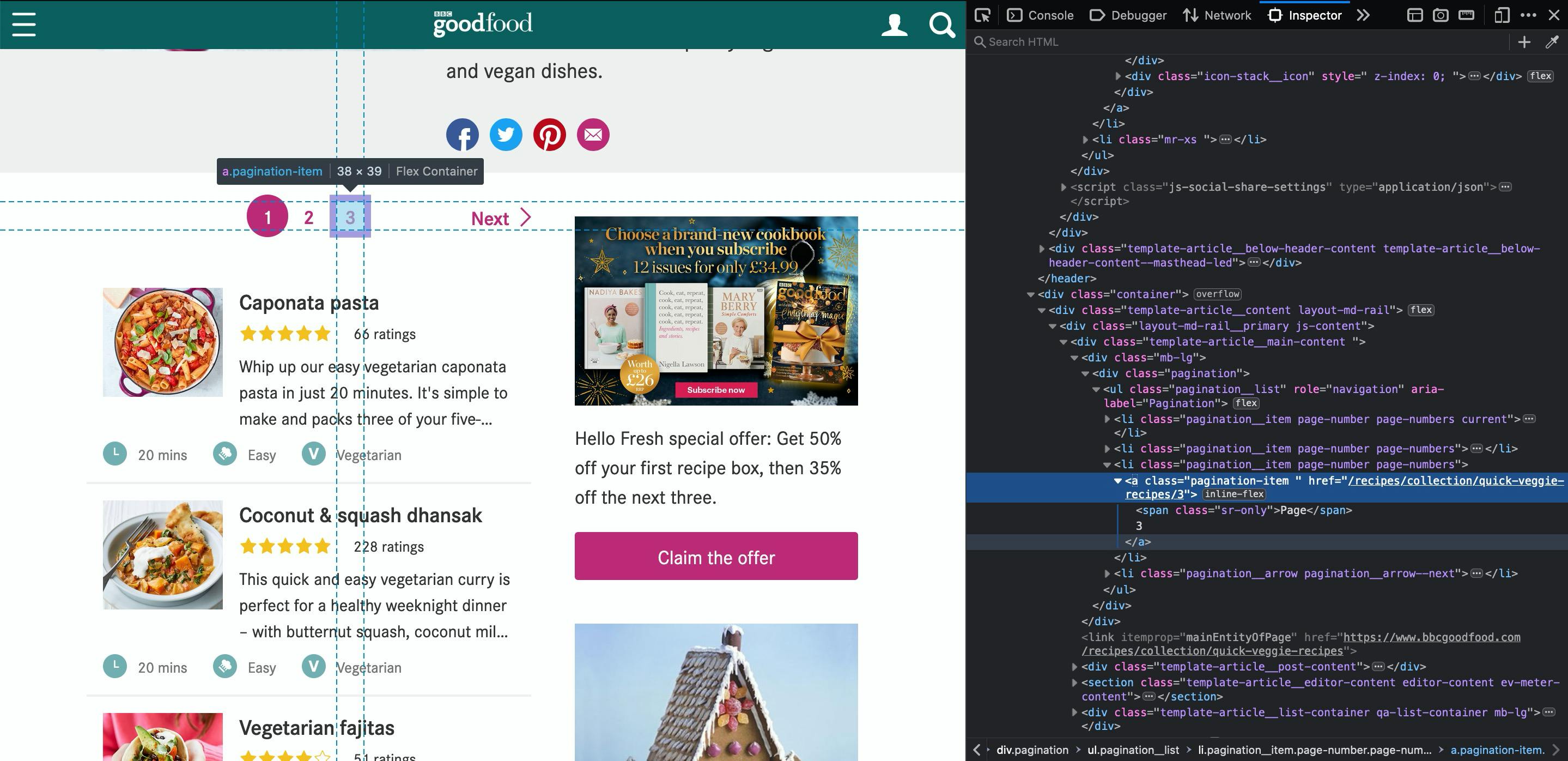
So, it has a CSS class called pagination-item. Let's do that quick test again in browser and see how many items do we get with that class
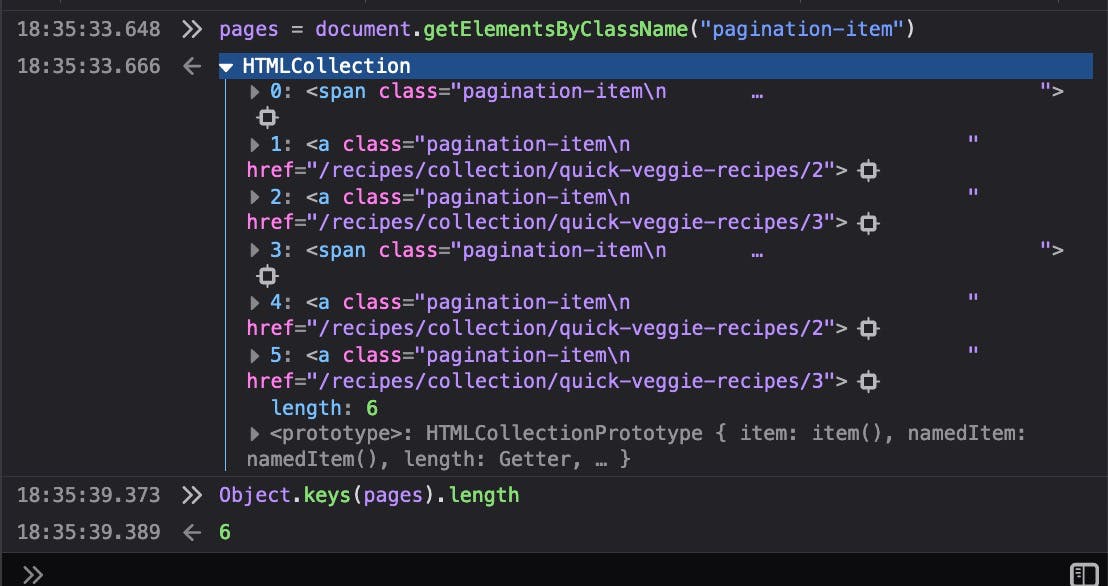
It returns 6 elements. The reason for that is that it has 2 paginations: one at the top and other at the bottom. And, if we look closely, we will see that 2 of those elements are a <span> and the other are <a>. This means the current page is a span, so there's no href parameter. Let's try something different: querySelector
links = document.querySelectorAll("a.pagination-item")
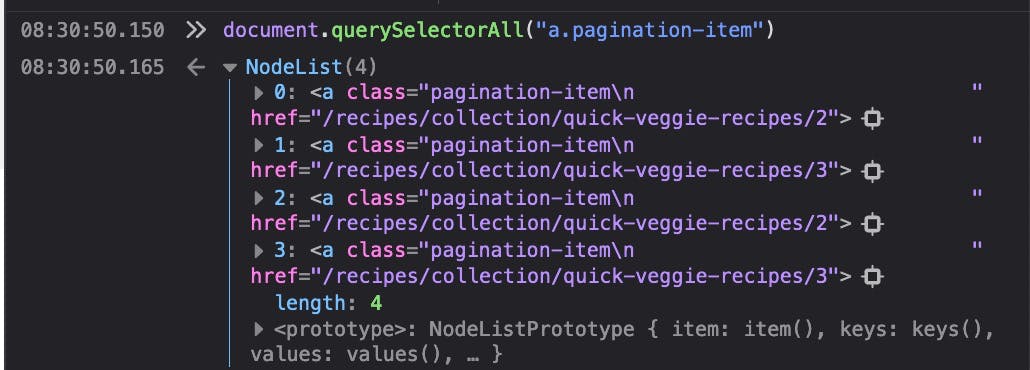
Cool, right? We have all the URLs for next pages, but duplicated. So, a simple way to solve that is to get the href from each element, store in an Set and it will automatically eliminate the duplicates for us! Super!
So, here's a first draft of our code
import jsdom from "jsdom";
const { JSDOM } = jsdom;
const MAIN_URL = "https://www.bbcgoodfood.com/recipes";
/**
* Get URLs with recipes list
* @returns {Array} Array with all URLs
*/
const getURLsWithRecipesList = async () => {
try {
const { window } = await JSDOM.fromURL(
`${MAIN_URL}/collection/quick-veggie-recipes`
);
const aTags = window.document.querySelectorAll("a.pagination-item");
const urls = new Set([`${MAIN_URL}/collection/quick-veggie-recipes`]);
for (const link of aTags) {
urls.add(link.href);
}
return [...urls];
} catch (error) {
console.error("Failed scraping", error.message);
throw error;
}
};
/**
* Get all recipes URLs from list
* @param {string} url Recipe list url
* @returns {array} List of recipes' URLs
*/
const getRecipeLinksFromUrl = async (url) => {
try {
const { window } = await JSDOM.fromURL(url);
const aTags = window.document.getElementsByClassName(
"standard-card-new__article-title qa-card-link"
);
const urls = new Set();
for (const link of aTags) {
urls.add(link.href);
}
return [...urls];
} catch (error) {
console.error("Failed scraping", error.message);
throw error;
}
};
const init = async () => {
const recipeUrls = await getURLsWithRecipesList();
const allRecipesLinks = new Set();
for (const url of recipeUrls) {
const recipeLinksFromUrl = await getRecipeLinksFromUrl(url);
recipeLinksFromUrl.forEach((link) => allRecipesLinks.add(link));
}
console.log(allRecipesLinks);
};
init();
We can simplify it by "merging" those 2 functions. They are very similar, right? If we replace the getElementsByClassName to querySelectorAll, they would be identical! Let's try it!
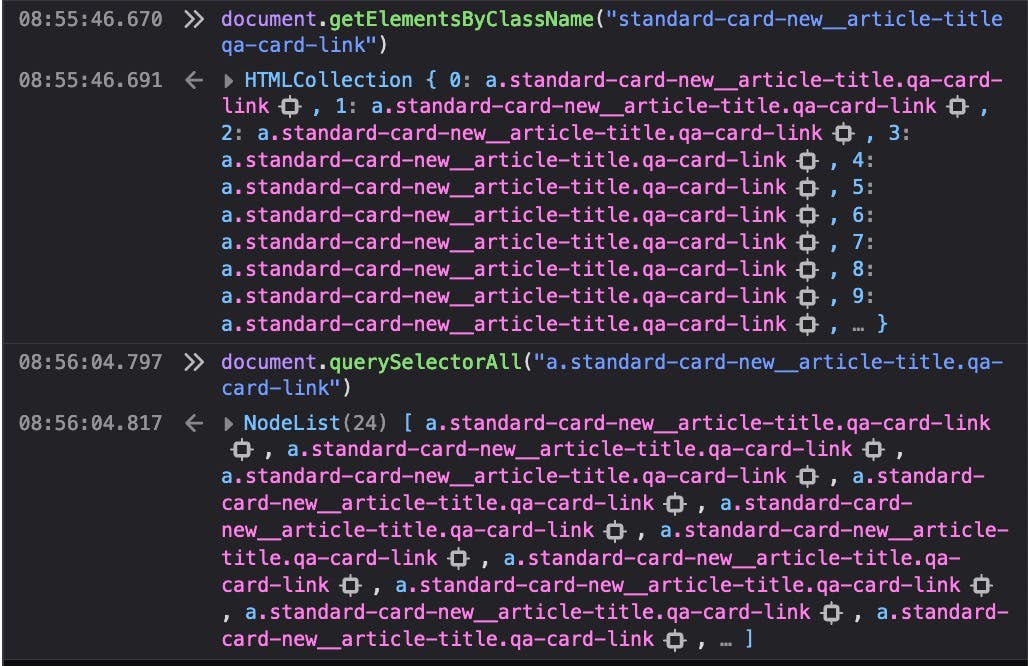
It works! Nice!! So, our final code to get the URLs of all recipes
import jsdom from "jsdom";
const { JSDOM } = jsdom;
const MAIN_URL = "https://www.bbcgoodfood.com/recipes";
/**
* Get HREF attributes from selectors in given URL
* @param {string} url URL to scrap
* @param {string} selector Selector to search in the DOM
* @returns {array} List of href found
*/
const getHrefAttrsFromUrlWithSelector = async (url, selector) => {
try {
const { window } = await JSDOM.fromURL(url);
const selectors = window.document.querySelectorAll(selector);
const urls = new Set();
for (const selector of selectors) {
urls.add(selector.href);
}
return [...urls];
} catch (error) {
console.error("Failed scraping", error.message);
throw error;
}
};
const init = async () => {
// Get all URLs that contains list of recipes
const recipeUrls = await getHrefAttrsFromUrlWithSelector(
`${MAIN_URL}/collection/quick-veggie-recipes`,
"a.pagination-item"
);
recipeUrls.unshift(`${MAIN_URL}/collection/quick-veggie-recipes`); // add first page to list
// Then, scrap each of those pages and get the URL of each recipe
const allRecipesLinks = new Set();
for (const url of recipeUrls) {
const recipeLinksFromUrl = await getHrefAttrsFromUrlWithSelector(
url,
"a.standard-card-new__article-title.qa-card-link"
);
recipeLinksFromUrl.forEach((link) => allRecipesLinks.add(link));
}
console.log(allRecipesLinks);
};
init();
Simpler and better! Great! On next post, we will scrap and save each recipe from the allRecipesLinks.