Week Meal Plan #4 - scraping each recipe from BBC Good Food


Let's keep moving, folks! We have all the URLs for all recipes we want to save. Now, let's see what we will have to do to scrap it. Let's use this Caponata recipe as example.
I checked if there were any API calls with a response containing the recipe and, noup... it's a static html file again. Ok, no problem! What we will need from this page is:
- title
- image
- description
- ingredients
- steps
Title
This should be one of the easiest. Usually a page has only 1 <h1> tag element and most probably it will have the title. Inspecting, there's also a CSS class we can use to get title if it fails using only the <h1>
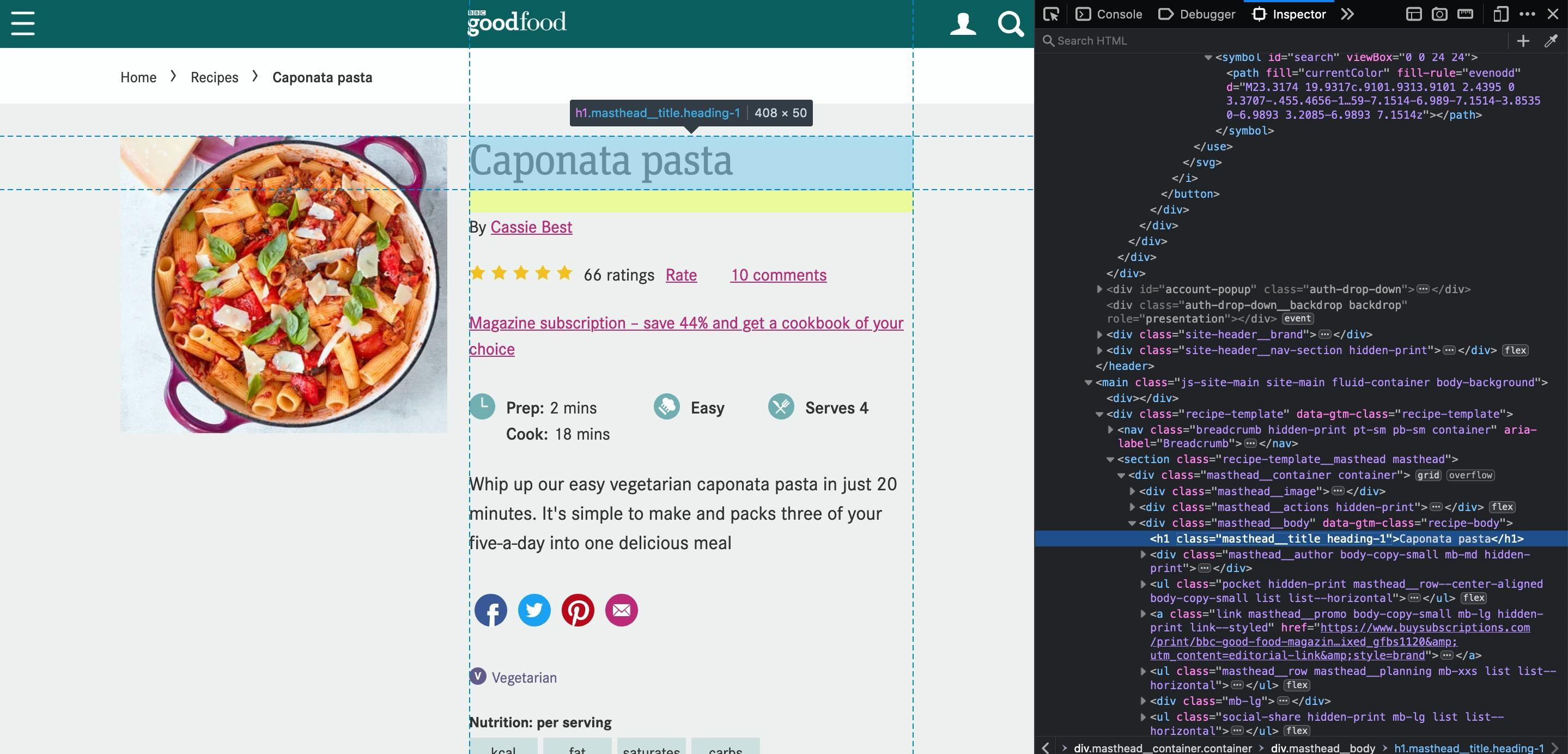
title = document.querySelector("h1").innerText;
Image
We have to find an <img> tag and grab the src from it. Inspecting where the image is, there's a class called masthead__image. Looks like it's not used anywhere else in the code, so it's a safe bet. Let's get this element and then select the img tag.
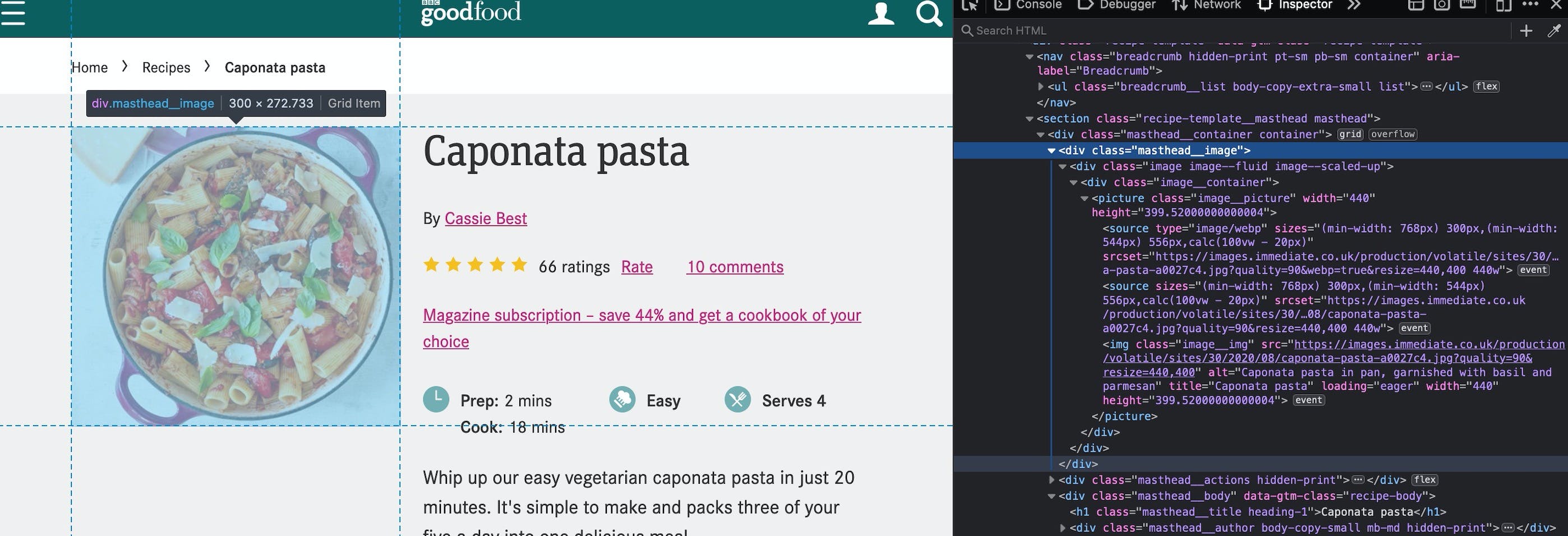
header = document.querySelector(".masthead__image");
image = header.querySelector("img").src;
Description
For the description, we have this editor-content css class that can help up.
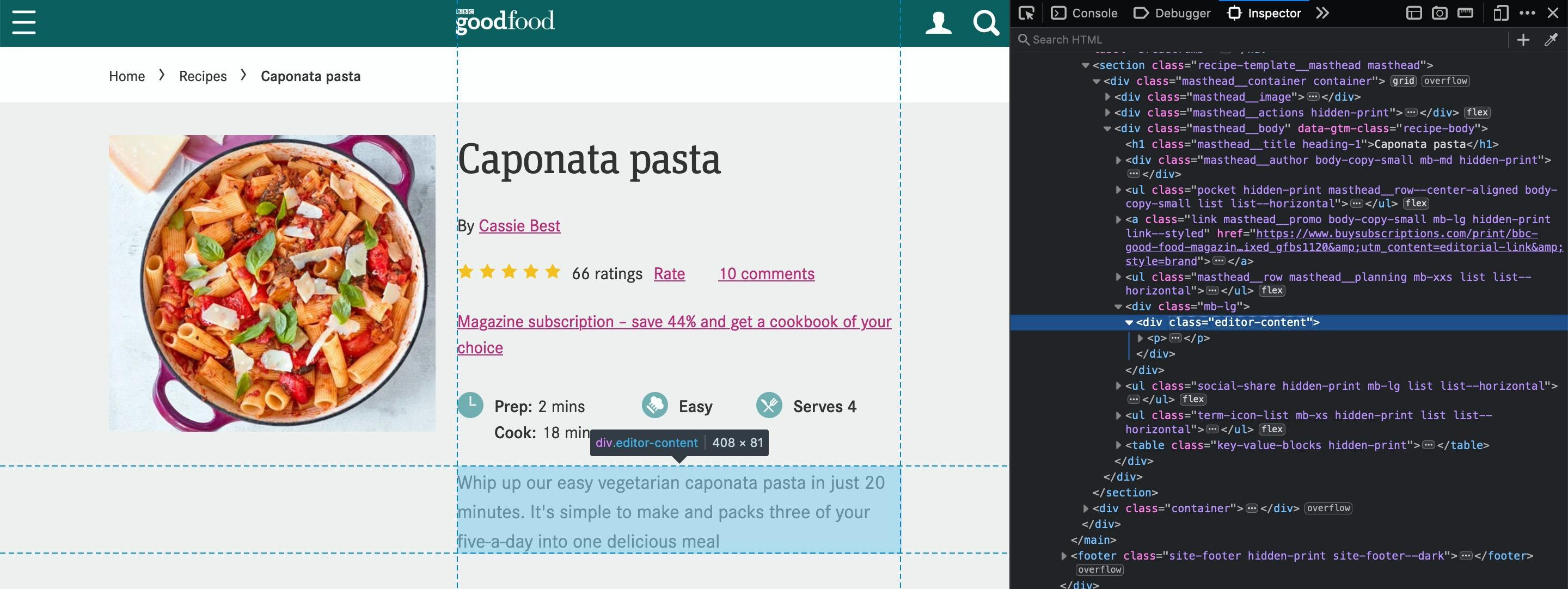
Let's inspect it
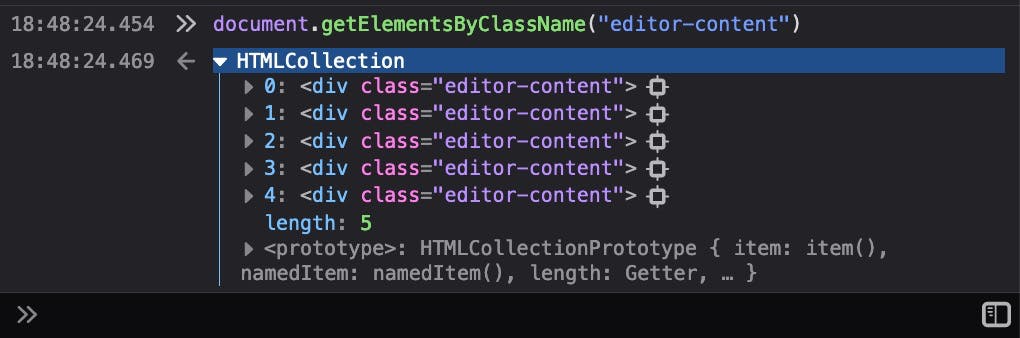
It give us 4 items... hmm... so, let's try using a parent class from the header: masthead__body class
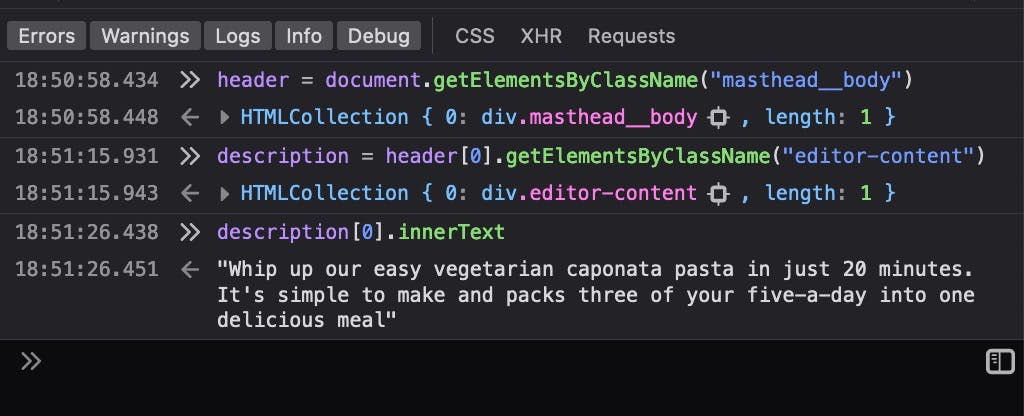
Oh yeah! It works! Here's the idea: we get the parent element (masthead__body) and then search on its children.
parents = document.getElementsByClassName("masthead__body");
children = parents[0].getElementsByClassName("editor-content");
description = children[0].innerText;
Ingredients
Look how beautiful is this! A class with ingredients on its name and right below a list with all ingredients!
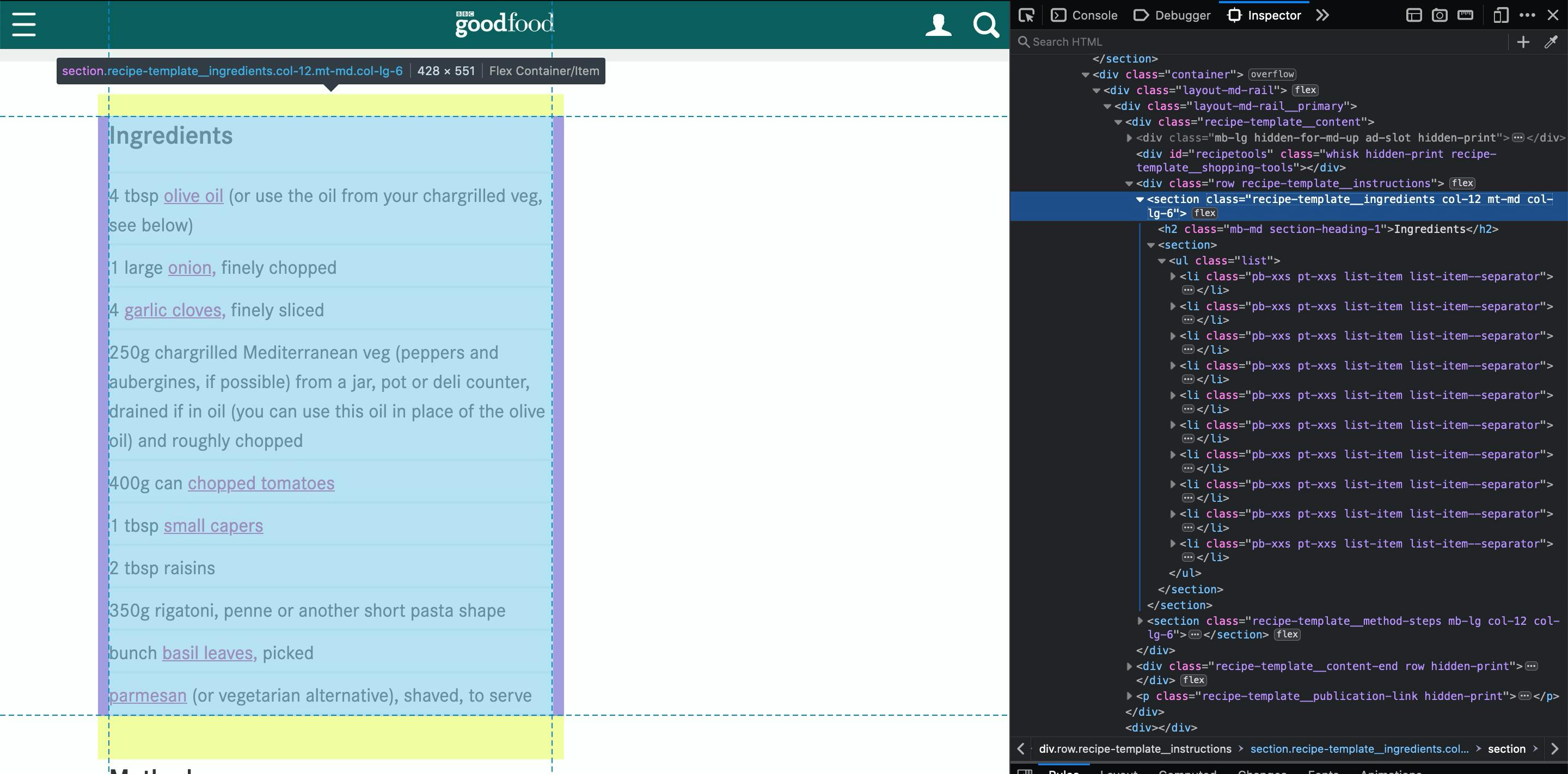
Here's the plan: get the element recipe-template__ingredients and then search on its children for all <li> elements and extract the text!
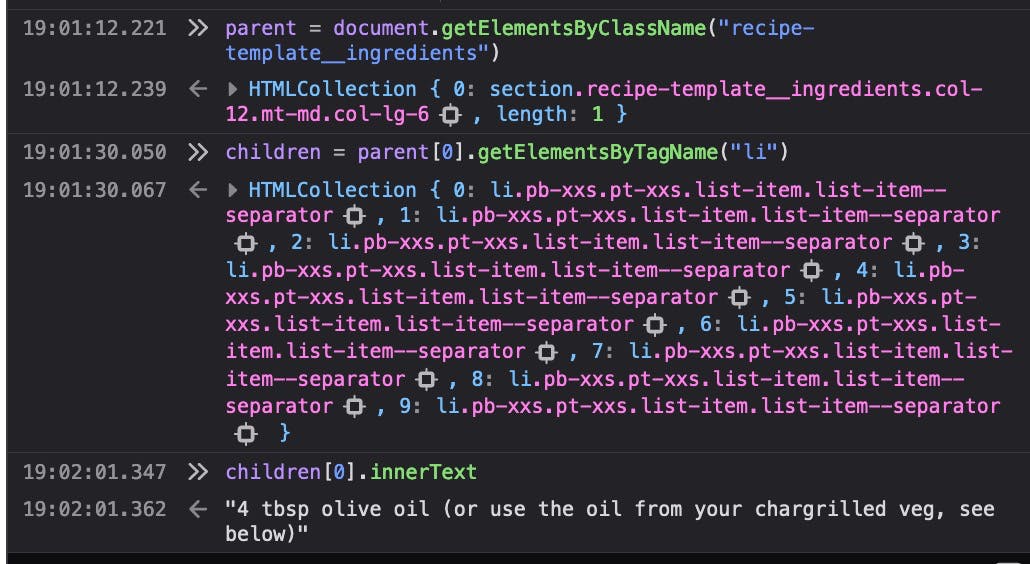
parent = document.querySelector(".recipe-template__ingredients");
children = parent.getElementsByTagName("li")
ingredients = []
for (const ingredient of children) {
ingredients.push(ingredient.innerText);
}
Steps
This will looks very similar to the ingredients step. The difference is, we will replace the recipe-template__ingredients class to recipe-template__method-steps
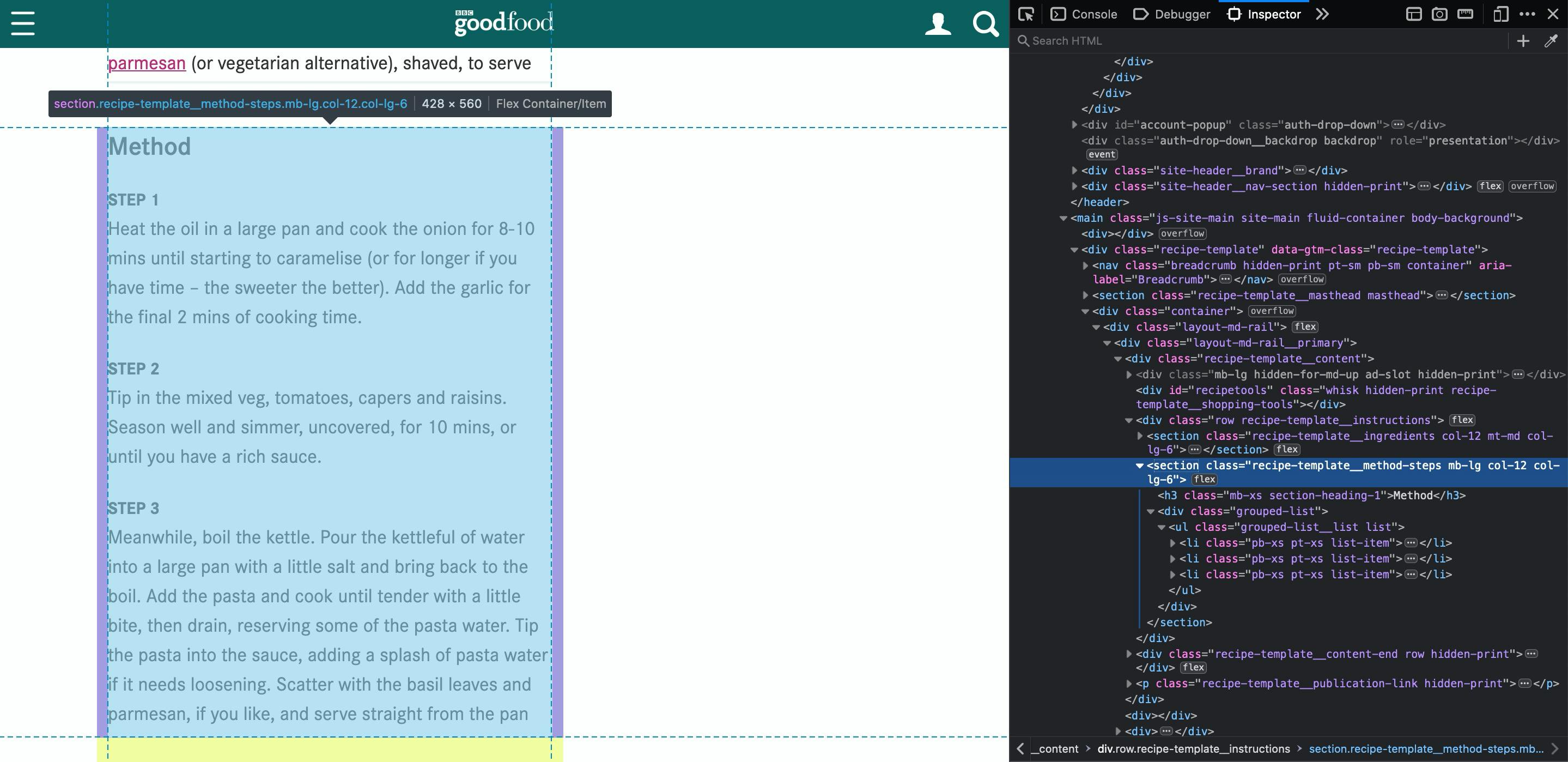
Inside of each step <li> tag, there's a <span> and a <div class="editor-content">. So, let's grab the innerText from ".editor-content" and we are all good!
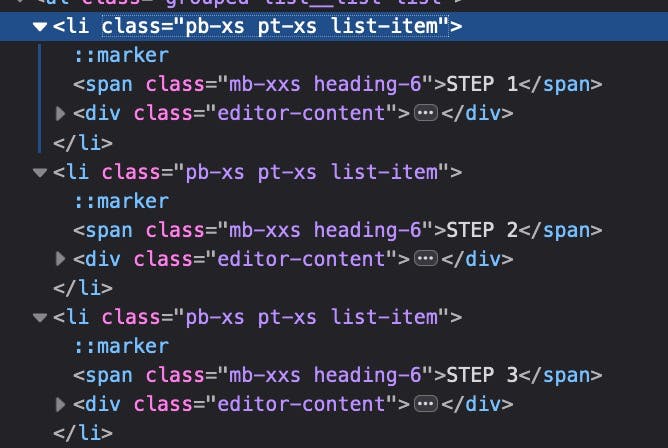
parent = document.querySelector(".recipe-template__method-steps");
children = parent.getElementsByTagName("li")
steps = []
for (const step of children) {
steps.push(
step.querySelector(".editor-content").innerText;
)
}
All right!! Let's dive into the final code now!
import jsdom from 'jsdom';
import cliProgress from 'cli-progress';
import fs from 'fs';
import { promisify } from 'util';
const { JSDOM } = jsdom;
const sleep = promisify(setTimeout);
const MAIN_URL = 'https://www.bbcgoodfood.com/recipes';
/**
* Get HREF attributes from selectors in given URL
* @param {string} url URL to scrap
* @param {string} selector Selector to search in the DOM
* @returns {array} List of href found
*/
const getHrefAttrsFromUrlWithSelector = async (url, selector) => {
try {
const { window } = await JSDOM.fromURL(url);
const selectors = window.document.querySelectorAll(selector);
const urls = new Set();
for (const selector of selectors) {
urls.add(selector.href);
}
return [...urls];
} catch (error) {
console.error('Failed scraping', error.message);
throw error;
}
};
/**
* Get all recipes URLs
* @returns {Set} List containing all URLs
*/
const getAllRecipesUrls = async () => {
// Get all URLs that contains list of recipes
const recipeUrls = await getHrefAttrsFromUrlWithSelector(
`${MAIN_URL}/collection/quick-veggie-recipes`,
'a.pagination-item'
);
recipeUrls.unshift(`${MAIN_URL}/collection/quick-veggie-recipes`); // add first page to list
// Then, scrap each of those pages and get the URL of each recipe
const allRecipesLinks = new Set();
for (const url of recipeUrls) {
const recipeLinksFromUrl = await getHrefAttrsFromUrlWithSelector(
url,
'a.standard-card-new__article-title.qa-card-link'
);
recipeLinksFromUrl.forEach((link) => allRecipesLinks.add(link));
}
return allRecipesLinks;
};
/**
* Scrap and save recipe in JSON format
* @param {string} url Recipe url
*/
const scrapAndSaveRecipeUrl = async (url) => {
const { window } = await JSDOM.fromURL(url);
const { document } = window;
const recipe = {
url: url,
title: null,
image: null,
description: null,
ingredients: [],
steps: []
};
// Title
recipe.title = document.querySelector('h1').textContent;
// Image
recipe.image = document
.querySelector('.masthead__image')
.querySelector('img').src;
// Description
recipe.description = document
.querySelector('.masthead__body')
.querySelector('.editor-content').textContent;
// Ingredients
const ingredients = [];
const ingredientsParent = document.querySelector(
'.recipe-template__ingredients'
);
for (const ingredient of ingredientsParent.getElementsByTagName('li')) {
ingredients.push(ingredient.textContent);
}
recipe.ingredients = ingredients;
// Steps
const steps = [];
const stepsParent = document.querySelector('.recipe-template__method-steps');
for (const step of stepsParent.getElementsByTagName('li')) {
steps.push(step.querySelector('.editor-content').textContent);
}
recipe.steps = steps;
// get the last occurrence of / and extract the text after it. This is the slug
const filename = url.substr(url.lastIndexOf('/') + 1);
fs.writeFile(
`recipes/${filename}.json`,
JSON.stringify(recipe, null, 2),
(err) => {
if (err) {
console.error(`Failed saving recipe ${recipe.slug}`, err);
}
}
);
};
const init = async () => {
const recipesUrls = await getAllRecipesUrls();
const progressBar = new cliProgress.SingleBar(
{
format: '{bar} |' + '| {value}/{total} recipes || Recipe: {recipe}'
},
cliProgress.Presets.shades_classic
);
progressBar.start(recipesUrls.size, 0, {
recipe: 'N/A'
});
if (!fs.existsSync('recipes')) {
fs.mkdirSync('recipes');
}
let index = 0;
for (const url of recipesUrls) {
index++;
progressBar.update(index, {
recipe: url
});
await scrapAndSaveRecipeUrl(url);
await sleep(3000); // to avoid server denying your requests
}
progressBar.update(recipesUrls.length);
progressBar.stop();
};
init();
You can check out the code and all recipes scraped in the Github repository
Next post we will think about how to store all those recipes in a database/file and recommend to user 5 recipes each week!
Let me know in the comments what you're thinking about this series! Cheers!!